かねてから気になっていたGitHub Copilotを試してみることにした。開発効率やコード品質の向上に繋げられるなら月額10$くらい安いものだが、その実力やいかに。
サインアップ
有償サービスなのでサインアップが必要である。自分が見たときは、クレジットカード/Paypalが使えるらしかった。クレジットカードを選択し、その情報と住所・名前を入力して確認すれば登録はすぐに完了した。
VSCodeを使うので、こちらのマニュアルからVSCodeに導入した。
連携の承認が必要だったが、イントロダクションに従ってポチポチクリックするだけであっけないほど完了。
迷うところは特になかった。
使ってみた
公式のAboutによれば、
GitHub Copilot is an AI pair programmer that offers autocomplete-style suggestions as you code. (GitHub Copilotはオートコンプリートでやるみたいにお勧めをあなたのコードに提供するAI ペアプログラマーだよ!)
だそうである。具体的にオートコンプリートはどのような場面で起動するのか、であるが、基本はコメントであるようだ。そこでコメントを下記のように記載してEnterを押すと
# ファイルを読み込む
下記のようなコードが表示された。
# ファイルを読み込む
def read_file():
# ファイルを開く
with open("data.txt", "r") as f:
# ファイルの内容を読み込む
data = f.read()
# ファイルを閉じる
f.close()
# ファイルの内容を返す
return data
TABを押すことで確定させられる。
"おいおい兄弟、ハードコーディングは勘弁してくれよ"と思うかもしれないが(自分は思った)、これはコメントのつけ方が悪い。下記のようにコメントを記載して出し直すと
# ファイルをファイル名から読み込む
ちゃんと引数を使った関数が表示された。素晴らしい。
# ファイルをファイル名から読み込む
def read_file(file_name):
# ファイルを開く
with open(file_name, "r") as f:
# ファイルの内容を読み込む
data = f.read()
# ファイルを閉じる
f.close()
# ファイルの内容を返す
return data
欲を言えば型もちゃんと指定してほしかったが、Pythonは型指定なしで書かれることも多いので、その影響だろう。十分、ともいえる。
ちなみに選択肢があればCTRL+Enterで複数の候補を表示させることもできる。
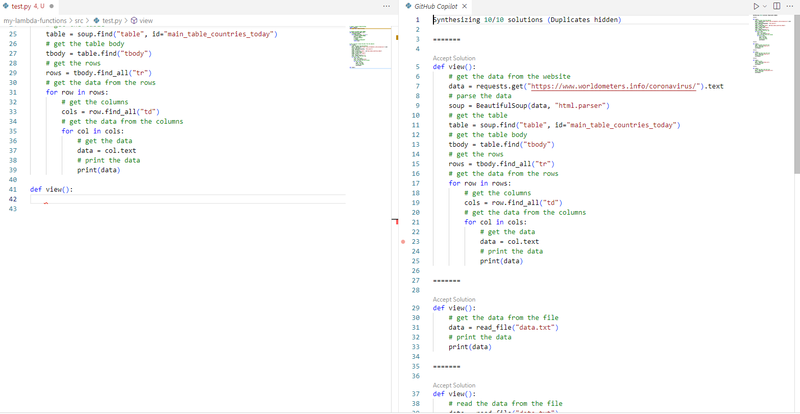
関数名が重要?
関数名に影響を受けるらしく、単純な動詞のほうが候補が出やすいようだ、scrapeだけであれば下記のようにそれらしいコードが表示されるのだが
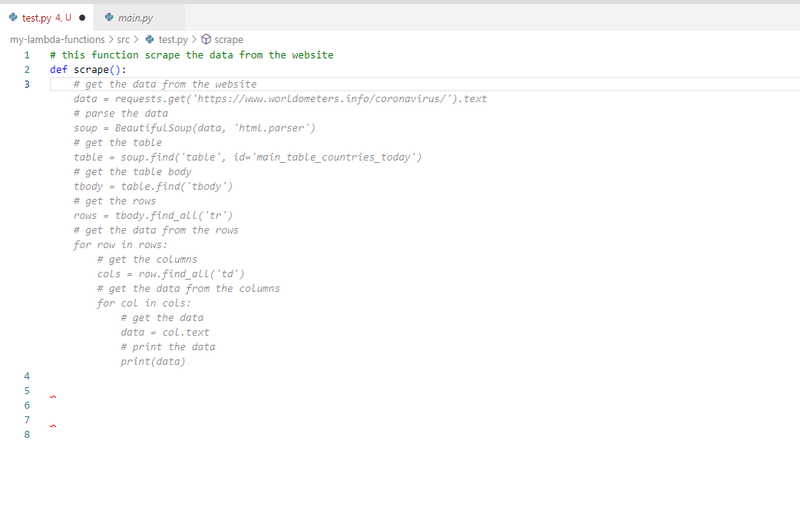
一方で、scrape_dataとすると候補が出なかった。
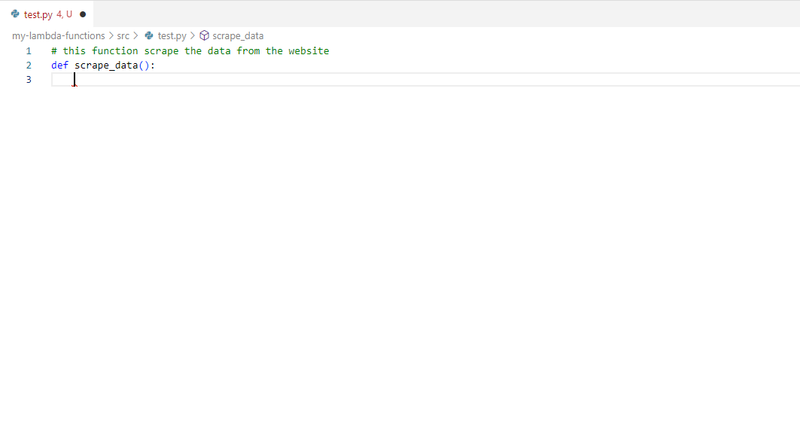
元々のコードのベースから確からしいコードを推測して出しているのだろうから、これは納得いく理由。今ある労働のいくつかは人がAIに合わせるようになるであろうと思っていたが、プログラミングの世界がすでにそうなっていたことを感じさせる。
具体的な、いわゆる下位問題を解決するための関数の作成には、かなりの威力を発揮しそうな雰囲気である。実に素晴らしい。
ある程度抽象的な関数にも対応してくれるのか?
理想は抽象的なビジネスモデルをブレイクダウンしてコードにまで落とし込んでくれることだが、さすがにそれは望み過ぎとして、実際どの程度であれば抽象的な問題にも対応できるのか。
というわけで下記のコード(C#)を自前で書いた上で、
class Member{
public int Id {get; set;}
public string Name {get; set;}
}
class MemberServiceで利用してみたところ、下記のようになった。
class MemberService{
public Member GetMember(int id){
return new Member {Id = id, Name = "John"};
}
public void SaveMember(Member member){
//save member
}
public void DeleteMember(int id){
//delete member
}
}
まあ悪くない。EFを使ってくれても良かったか? しかしこんなものだろう。
むしろ驚いたのはTestMemberServiceと打ってCTRL+Enterで候補を一覧表示させたときのことで、なんと下記のようなコードが表示された。
class TestMemberService{
public void TestGetMember(){
MemberService memberService = new MemberService();
Member member = memberService.GetMember(1);
Assert.AreEqual(1, member.Id);
Assert.AreEqual("John", member.Name);
}
public void TestSaveMember(){
MemberService memberService = new MemberService();
Member member = new Member {Id = 1, Name = "John"};
memberService.SaveMember(member);
//assert if member is saved
}
public void TestDeleteMember(){
MemberService memberService = new MemberService();
memberService.DeleteMember(1);
//assert if member is deleted
}
}
なにこれ凄い。しかも驚いたことに、既存クラスのプロパティが変わると追跡した(!)。これは楽である。
実際どう?
もっと使ってから判断すべきではあるが、極めて便利なツールと感じる。少なくとも自分の中では、プログラミングを行い続ける間、Github Copilotを是非使い続けたいと思う。
